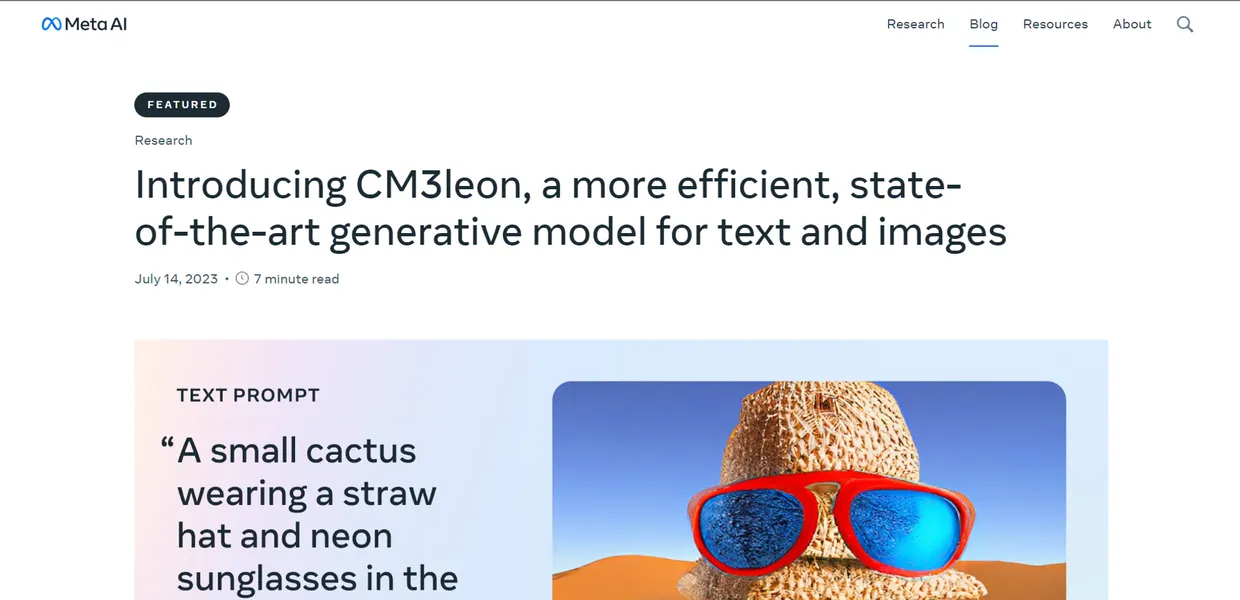
What is CM3leon?
The most frustrating aspect of Meta’s CM3leon is its strict exclusivity. Despite achieving high-quality image generation using five times less training compute than previous models, you cannot sign up and use it.
Meta Platforms developed this multimodal foundation model to solve the inefficiency of separate text and image systems. CM3leon uses a single transformer architecture (a rare approach for this category) to process both text and image tokens. It targets enterprise research teams and large-scale digital asset managers who need precise control over visual outputs.
- Primary Use Case: Generating high-resolution marketing assets with precise spatial bounding box constraints.
- Ideal For: Enterprise machine learning teams with access to high-end GPU clusters.
- Pricing: Starts at $Custom (Enterprise) – Requires contact with Meta for access and deployment terms.
Key Features and How CM3leon Works
Bidirectional Generation
- Text-to-Image Generation: Produces 1024×1024 images from text prompts, limited by the need for a dedicated super-resolution stage to achieve maximum clarity.
- Image-to-Text Captioning: Writes context-aware descriptions for uploaded images, though accuracy depends on the clarity of the source material.
How does this model handle complex layouts?
Advanced Visual Control
- Spatially Conditioned Generation: Accepts bounding box inputs to define exact object locations, restricted to the spatial grid resolution of the model.
- Image-guided Editing: Modifies existing images using text instructions, limited by the model’s interpretation of complex multi-step commands.
Architecture and Training
- Unified Tokenization: Processes text and image tokens interchangeably, requiring massive initial compute to train the joint vocabulary.
- Retrieval-Augmented Training: Uses external data sources during inference to improve factual accuracy, limited by the quality of the connected database.
CM3leon Pros and Cons
Pros
- Achieves top-tier results using five times less training compute than models like DALL-E 2.
- Trained only on licensed Shutterstock data, reducing copyright risks for enterprise users.
- Excels at both generating images and describing them within a single framework.
- Spatial conditioning allows users to dictate exact object placement using bounding boxes.
Cons
- Restricted to research and enterprise partners with no consumer web interface.
- Meta keeps the model weights closed to the open-source community.
- Real-time inference requires expensive enterprise hardware like NVIDIA H100 GPUs.
Who Should Use CM3leon?
- Enterprise AI Researchers: Teams studying multimodal transformer architectures can study its efficient tokenization methods.
- Large Digital Asset Managers: Companies needing automated alt-text generation for massive image libraries will benefit from its captioning speed.
- Solo Creators and Hobbyists: This tool is not for you. The lack of a public interface and high hardware requirements make it impossible for casual users to adopt.
CM3leon Pricing and Plans
Meta does not offer a public pricing tier or a free trial for CM3leon.
- Contact for Pricing: Custom limits apply based on enterprise agreements. This tier provides access to the foundation model for text-to-image and image-to-text transformations. You must negotiate API limits and deployment terms with Meta.
How CM3leon Compares to Alternatives
Similar to DALL-E 3, CM3leon generates high-fidelity images from complex natural language prompts. Unlike DALL-E 3, which integrates into ChatGPT for easy consumer access, Meta restricts CM3leon to enterprise partners. DALL-E 3 struggles with precise object placement, whereas CM3leon uses spatial bounding boxes to give users exact layout control.
Midjourney competes in raw image quality and artistic styling. Midjourney operates through Discord and a web alpha (which requires a paid subscription), making it accessible to solo creators. CM3leon requires significant machine learning expertise to deploy on private servers. However, CM3leon offers a safer legal foundation because Meta trained it on licensed Shutterstock images.
Verdict: Enterprise Teams Needing Strict Layout Control
Large organizations with dedicated machine learning engineers will get the most value from CM3leon. Its licensed training data and precise bounding box controls solve major enterprise compliance and design issues.
Solo developers and small marketing teams should look elsewhere.
If you need high-quality image generation without the massive technical overhead, DALL-E 3 remains the most practical alternative.